网络安全
开源
lcd
wpf
gazebo
自定义watermark
Android蓝牙使能
USB转JTAG
增强现实
图相似度预测
supervisor
山区监视场景建模
风控数据分析师
bug
微软
proteus
LabVIEW编程
企业管理
k8s
秒定时器
spark-ml
2024/4/11 12:30:05
Spark MLlib简介与机器学习流程
在大数据领域,机器学习是一个关键的应用领域,可以用于从海量数据中提取有价值的信息和模式。Apache Spark MLlib是一个强大的机器学习库,可以在分布式大数据处理环境中进行机器学习任务。本文将深入介绍Spark MLlib的基本概念、机器学习流程以…

Spark面试整理-解释Spark MLlib是什么
Apache Spark的MLlib(Machine Learning Library)是一个构建在Spark之上的机器学习库,旨在处理大规模的数据分析和挖掘任务。MLlib提供了一系列高效的算法和工具,这些工具被设计为可扩展和易于集成到大数据应用和流程中。以下是Spark MLlib的一些主要特点: 1. 广泛的机器学…
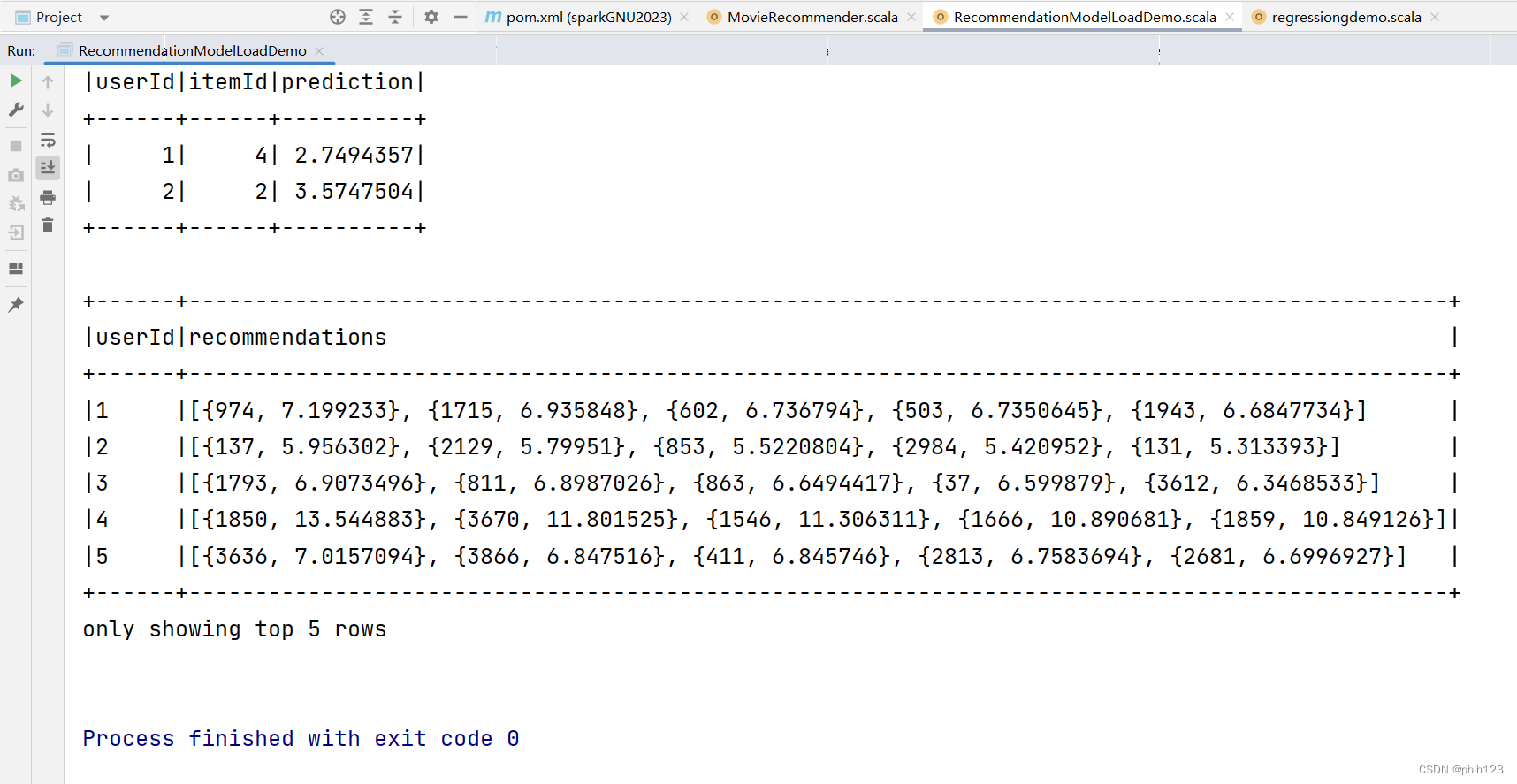
基于Scala开发Spark ML的ALS推荐模型实战
推荐系统,广泛应用到电商,营销行业。本文通过Scala,开发Spark ML的ALS算法训练推荐模型,用于电影评分预测推荐。
算法简介
ALS算法是Spark ML中实现协同过滤的矩阵分解方法。
ALS,即交替最小二乘法(Alte…
Java应用|使用Apache Spark MLlib构建机器学习模型【下】
如果您觉得本博客的内容对您有所帮助或启发,请关注我的博客,以便第一时间获取最新技术文章和教程。同时,也欢迎您在评论区留言,分享想法和建议。谢谢支持! 四、无监督学习
4.1 聚类
4.1.1 K-Means
K-Means是一种常见…
入门指南:使用Spark MLlib进行数据处理和机器学习
引言: 在当今大数据时代,数据处理和机器学习成为了许多企业和数据科学家的核心任务。然而,处理大规模数据和训练复杂的机器学习模型并不容易。幸运的是,Apache Spark提供了一个强大的机器学习库,即Spark MLlib…
![[机器学习、Spark]Spark MLlib实现数据基本统计](https://img-blog.csdnimg.cn/49cdef29457147078e3ef718b02237c7.png)
[机器学习、Spark]Spark MLlib实现数据基本统计
👨🎓👨🎓博主:发量不足
📑📑本期更新内容:Spark MLlib基本统计
📑📑下篇文章预告:Spark MLlib的分类🔥🔥
简介&…
【头歌实训】Spark MLlib ( Python 版 )
文章目录 第1关:基本统计编程要求测试说明答案代码 第2关:回归编程要求测试说明参考资料答案代码 第3关:分类编程要求测试说明参考资料答案代码 第4关:协同过滤编程要求测试说明参考资料答案代码 第5关:聚类编程要求测…
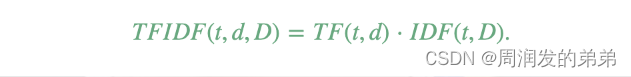
【SparkML系列3】特征提取器TF-IDF、Word2Vec和CountVectorizer
本节介绍了用于处理特征的算法,大致可以分为以下几组:
提取(Extraction):从“原始”数据中提取特征。转换(Transformation):缩放、转换或修改特征。选择(Selection&…
【SparkML系列1】相关性、卡方检验和概述器实现
Correlation(相关性)
计算两组数据之间的相关性在统计学中是一种常见的操作。在spark.ml中,我们提供了计算多组数据之间成对相关性的灵活性。目前支持的相关性方法是皮尔逊(Pearson)相关系数和斯皮尔曼(Spearman)相关…
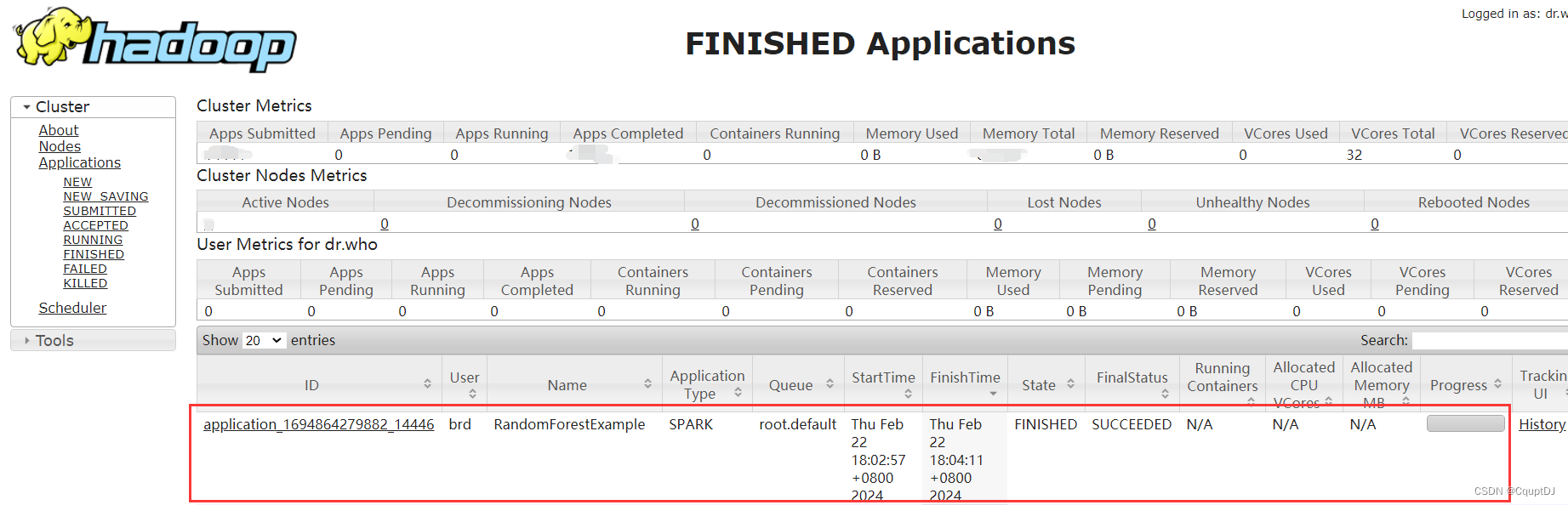
pyspark分布式部署随机森林算法
前言
分布式算法的文章我早就想写了,但是一直比较忙,没有写,最近一个项目又用到了,就记录一下运用Spark部署机器学习分类算法-随机森林的记录过程,写了一个demo。
基于pyspark的随机森林算法预测客户
本次实验采用的…
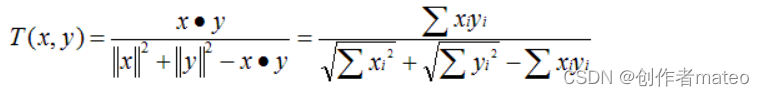
Spark MLlib ----- ALS算法
补充
在谈ALS(Alternating Least Squares)之前首先来谈谈LS,即最小二乘法。LS算法是ALS的基础,是一种数优化技术,也是一种常用的机器学习算法,他通过最小化误差平方和寻找数据的最佳匹配,利用最小二乘法寻找最优的未知数据,保证求的数据与已知的数据误差最小。LS也被用…

(一)PySpark3:安装教程及RDD编程(非常详细)
目录
一、pyspark介绍
二、PySpark安装
三、RDD编程
1、创建RDD
2、常用Action操作
①collect
②take
③takeSample
④first
⑤count
⑥reduce
⑦foreach
⑧countByKey
⑨saveAsTextFile
3、常用Transformation操作
①map
②filter
③flatMap
④sample
⑤d…
【机器学习】Spark ML 对数据进行规范化预处理 StandardScaler 与向量拆分
什么数据规范化?
规范化(Normalization)是一种数据预处理技术,用于将不同范围的特征值映射到相同的范围内。其中,StandardScaler 是一种规范化的方法,它将特征值转换为均值为 0、方差为 1 的标准正态分布。…
SparkML机器学习
SparkML
机器学习: 让机器学会人的学习行为, 通过算法和数据来模拟或实现人类的学习行为,使之不断改善自身性能。
机器学习的步骤: 加载数据特征工程 数据筛选: 选取适合训练的特征列, 例如用户id就不适合, 因为它特性太显著.数据转化: 将字符串的数据转化数据类型…

【Spark-ML源码解析】Word2Vec
前言
在阅读源码之前,需要了解Spark机器学习Pipline的概念。 相关阅读:SparkMLlib之Pipeline介绍及其应用 这里比较核心的两个概念是:Transformer和Estimator。 Transformer包括特征转换和学习后的模型两种情况,用来将一个DataFr…